启汀大数据解决方案基于启汀开发框架、提供一套全面集成的元计算服务及高内聚低耦合的资源整合,支持大数据的分布式架构的、纵向和横向的无限切分的高并发数据集合的解决方案。
启汀大数据从大数据的特征定义理解行业对大数据的整体描绘和定性;从对大数据价值的探讨来深入解决大数据的核心技术;洞悉大数据的发展趋势;从大数据安全与隐私这个特别而重要的视角审视人和数据之间的长久博弈。
技术是大数据价值体现的手段和前进的基石。启汀大数据解决方案分别从云计算、分布式处理技术、存储技术中抽象、提炼、归纳。形成启汀大数据从采集、处理、存储到形成结果、查询统计分析的整个过程。
大数据的处理的核心是可无限扩展服务器和与之相对应的分布式算法,数据库分布式,其核心内容无非就是数据切分(Sharding),以及切分后对数据的定位、整合工作,解决单一数据库或数据表因数据量过大而导致的性能瓶颈问题。集数据存储、管理以及分布式协调与计算为一体的数据库系统。数据切分就是把数据分散存放到多个数据库或多个表中,使得单台主机中的数据量变小,使得通过扩充主机数量即可提升数据库操作性能的目的。
数据切分可分为纵向和横向两种切分方法。纵向切分就是根据业务耦合性,将关联度低的不同表独立建成不同的数据库,如下图所示:
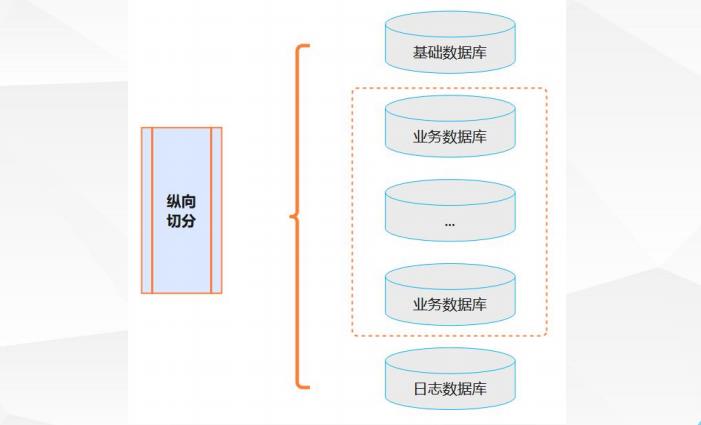
纵向切分相对简单,做法与我们将一个大的系统拆分成几个小系统的做法相似,就是根据业务分类进行独立划分应用或数据库。然而当一个应用已经难以再进一步拆分时,或者拆分后数据行数巨大时,我们就还需要进行横向切分(即:将单个表的记录数变小)。横向切分是根据表内数据的逻辑关系,将同一个表按不同的条件拆分到多个数据库或多个表中,如下图所示:
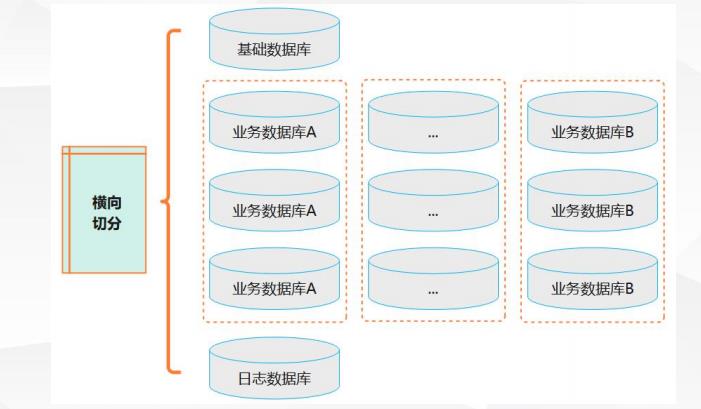
如上图所示,横向切分后同一张表同时出现在多个数据库中,每个库的数据内容不同,如何设定数据记录的切分规则是最重要考量。一旦确定切分规则,应用对该表的操作原则基本就已确定。
因此大数据的终极解决方向为数据的横向切分,理论上由此可以衍生出无数的分布式数据库,但对于这些切分后的数据库,如何有效的进行调用、查询统计等数据的调度,是大数据切分的成败的标志。
启汀大数据解决方案提出的可行性方法为,通过系统的config配置,抽象出数据的宏观性标志,将此标志传递到系统底层进行运算,同时,在表现层提供相应的大数据处理功能,并且在大数据调用过程中,通过启动开发框架自动进行处理,即启汀开发框架底层已经预设了大数据处理的相关机制,一旦启动,即可确保大数据在调度上的稳定性、安全性、准确性、高效性